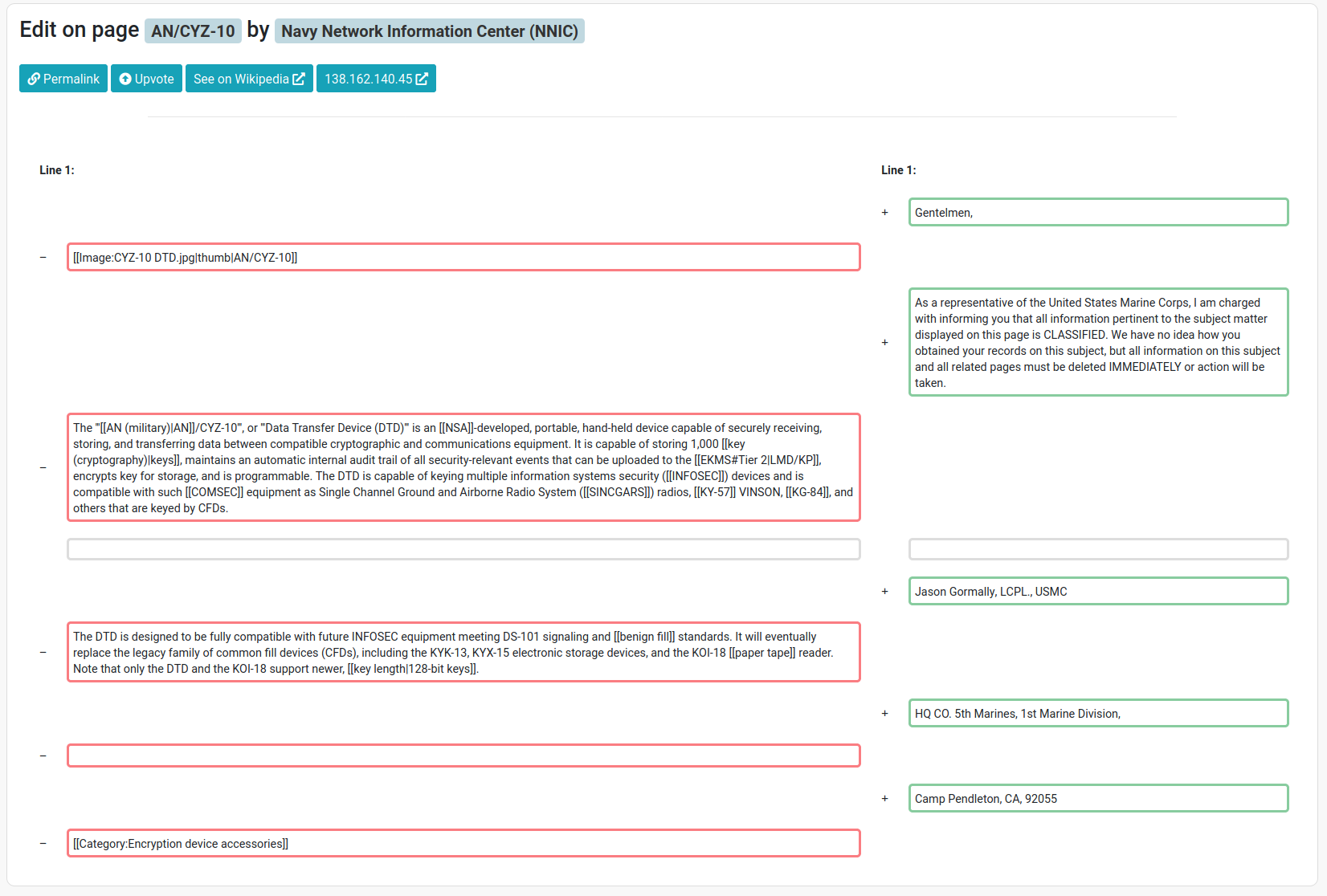
A couple of months ago, an idea came to mind of analyzing Wikipedia edits to discover which public institutions, companies or government agencies were contributing to Wikipedia, and what they were editing.
After a quick Google search I realized that it had been done before, but the service, called WikiScanner, had been discontinued in 2007. After WikiScanner, the idea surfaced again several years later: in 2014 the @congressedits Twitter account was created, which automatically tweeted any Wikipedia edit made by IP addresses belonging to the U.S. Congress. The account was eventually suspended by Twitter (read why here). The code for this bot was released under a CC0 license on Github, and several other bots were created, looking for edits from different organizations.
At the moment of this writing, some of these systems are still active on Twitter (e.g., @parliamentedits), but my interest was in building something that allowed users to search and navigate edits efficiently (rather than just having a stream of tweets), and that was not limited to monitor a single organization. I decided to dedicate some of my free time to this side project and build Wikiwho.
Methodology
I decided to use the same approach that WikiScanner used, which is to identify organizations based on their IP address. This is possible because, when somebody edits Wikipedia without being logged in, his IP address will be logged instead of his username. It follows that this system is not able to identify edits made by logged in users, which are simply discarded during a pre-processing step.
Each log entry contains metadata about the edit, e.g., time, IP address, edited page, but does not provide any information on what was actually edited. This already allows us to perform some analysis, e.g., which organizations are the most active, which pages have been edited the most and by who, which periods of time saw the most activity, etc…
However, this doesn’t give us any insight as to what was actually changed in the content of the page. To achieve this we need to use Wikipedia’s APIs in order to retrieve, for each edit, the diff with respect to the previous version of the same page. This way we can see what text was actually added or removed.
At this point, we have a huge amount of diffs with full information. To put this all together and allow an easy navigation I built a web interface on top of this data. The stack I’m using is Java, MongoDB for storing most of the data, and Lucene to enable full-text search. The following contains an overview of my implementation at a very high level.
1. Determining IP ranges of interest
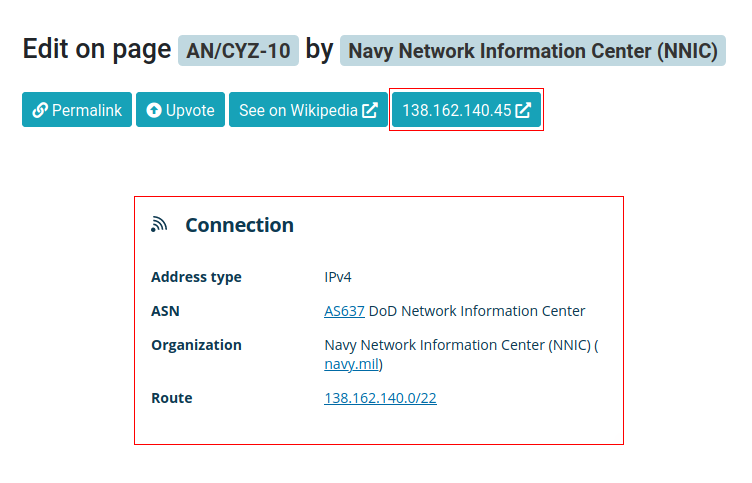
Since we are going to identify organizations based on the IP address, we need a mapping between IP address ranges and organizations. To avoid compiling this list myself, I have used IP ranges available at [1] and [2] (I may have used some other source as well, but I actually am not sure at the moment since this was a few months ago). It goes without saying that I cannot vouch for the accuracy of these lists. I’ve made a small amount of minor edits where I found obvious mistakes, but nothing more than that.
However, the final interface provides a way to quickly check if the information about the IP address is wrong:
2. Parsing Wikipedia dumps
Wikipedia edit history is released periodically in an XML format. There are several types of dumps: the one we are interested in is enwiki-$DATE-stub-meta-history.xml.gz, which contains the full edit history (only metadata).
The key elements in these dumps are revision nodes: for each revision, we will use its unique ID (to later retrieve its content with Wikipedia’s APIs), the IP address of the contributor and the timestamp to allow analyzing edits by date ranges. The XML for these nodes looks like this:
<revision>
<id>186146</id>
<parentid>178538</parentid>
<timestamp>2002-08-28T05:53:36Z</timestamp>
<contributor>
<ip>216.235.32.129</ip>
</contributor>
<model>wikitext</model>
<format>text/x-wiki</format>
<text bytes="9959" id="186146" />
<sha1>mau31t4o85dh1ksu79r1xvgs2dujr8c</sha1>
</revision>
You’ll need to use an event-based XML parser as the file is too big to fit in memory. We can iterate over the dump and extract a list of edits where the IP belongs to one of the ranges that we have defined at the previous step. I discarded revisions where the contributor field contains a username or a IPv6 address.
3. Calling the Wikipedia APIs
We still need to get the actual content of the diff. The request to Wikipedia’s APIs looks like this:
https://en.wikipedia.org/w/api.php?action=compare&fromrev=27272&torelative=prev&prop=diff|size|ids|title&format=json
fromrev is the ID of the revision we are interested in. Then, we can either specify another revision ID that we want to compare our revision with (using torev) or, if we want to compare with the previous revision, use torelative=prev. This way we do not have the hassle of retrieving the ID of the previous revision ourselves when parsing the XML dump. The prop parameter simply defines the fields we want in our output. This is what you get as a response.
The diff field contains an HTML-formatted version of the text, in which additions and deletions are marked by specific tags. It is basically what is shown if you open the diff in the Wikipedia comparison tool. After a few HTML parsing steps, we are now aware of what was actually added or removed. This is not really a necessary step, as we could have simply indexed the full text of the diff, bu doing so allows us to perform full-text search specifically for added or removed text.
4. Putting it all together
At this point we have a huge dump of JSON objects containing detailed information about every edit. We know who made it, what changed, and when. We have technically extracted all the information we need, we just need an efficient way of exploring it.
This last part is quite boring and just revolves around processing the diffs, computing stats, storing the info in some sort of database, and build an interface on top of it. To save development time, I decided to use the stack I’m most familiar with: a Java backend, MongoDB for storing stuff and Lucene to enable full-text search. Since I’m not really fond of working with Javascript, everything is rendered on the server side and JS usage is limited to where it’s absolutely necessary.
5. The final result
If you want to take a look, you can see the tool in action here.
It allows you to:
- Look at the history of edits of a specific page/organization;
- Look at how edits for a page/organization are distributed over time, and filter for a specific month;
- Full-text search for removed/added text;
- Upvote interesting edits (anonymously, no need to sign-up). Most voted edits are shown on the home page, hopefully something interesting will get to the top.
5.1 A note on full-text search
Using Lucene allows to perform some advanced queries to bring up more relevant results. Here’s a non-exhaustive list of the possibilities:
"exact phrase search": use quotes to look for an exact phrase;+wikipedia -google: use+and-operators to include/exclude particular words;wiki*: use wildcard operators;"wikipedia google"~N: proximity search: look for two words at maximum distanceN(in number of words).
6. Conclusions
From my own exploration, most of the stuff you can find is just vandalism or trolling, and I highly doubt that you will find anything of relevance. Some of the edits are really hilarious, though!
Overall, this was a really fun project to implement and I hope you’ll have some fun exploring the system and sharing your finds with everybody else.
See you!
