Update (24 June 2022): The code for this tool is now released on Github.
I’ve always been interested in automatic content creation, be it text or pictures (e.g., fractal art and similar). Just very recently, though, I found myself brainstorming ever so often about what kind of videos could be automatically generated with a decent enough quality (for a very generous definition of decent). After several ideas that were mostly too complex to implement in a reasonable amount of time, I realized that there could be a way to create engaging videos automatically, based on the content of a Wikipedia page.
Wikipedia is perfect because every major topic is usually covered in great detail, and there are hundreds of such topics so that our approach can be tested in a variety of settings.
The basic idea is to create a video that will illustrate the content of the Wikipedia page: the audio track will be made of its text while the video part will be a slideshow of pictures of the topic at hand, extracted from Wikipedia and other sources. As I started experimenting and building the system, I came across several issues and possible improvements to this basic concept, so keep reading if I’ve piqued your interest!
1. Design of the system
Our only requirement is that the system will work with any Wikipedia page, with no more user input than the title of the page itself. It will output an mp4 file with the final video with no human intervention. The system will work in the following way:
- Get a Wikipedia page in input and retrieve its content;
- Parse it to define the structure of the video: we want to divide the video in multiple sections following the structure of the page;
- Retrieve any other additional information from e.g., Wikidata and pictures/videos from Pixabay;
- Build a storyboard that will show us how the final video will look like, before rendering it;
- Render the audio with a text-to-speech engine (I used Amazon Polly);
- Render the video with ffmpeg.
Here are some pieces of tech that I used to achieve this:
- Wikipedia APIs: used to retrieve the content of the Wikipedia page;
- Wikidata APIs: used to extract additional information about the current page and displaying it in the video;
- Pixabay APIs: free, open-domain image/video search APIs, to retrieve related content to show;
- Amazon Polly: text-to-speech engine to render the audio;
- ffmpeg: used for rendering the video itself.
I built everything with Java, so a bunch of other libraries have been used (e.g., Jsoup for HTML parsing) but I will not go into language-specific details and rather show the system at a high level.
1.1 Retrieve Wikipedia page content
In itself, retrieving the content of a page is very easy with Wikipedia APIs. The only thing we need to take into account is that we will need it for two purposes:
- Read the text out loud using TTS;
- Extract the structure of the page (read next section to know why)
We can get the content in three different formats: plaintext, Wiki markup language or HTML. The plaintext version is definitely the one we will use for the TTS engine, as we do not want it to read any markup. As for extracting the structure, parsing Wiki markup language is hell, so we’ll go with HTML. Thus, for each page, we will make two requests: one to get its plaintext and one for the HTML version.
1.2 Parse Wikipedia page content and define video structure
Every Wikipedia article is divided in sections and sub-sections. As the name implies, a section can contain other sub-sections, as it happens for “History” in the following screenshot (“Earliest history”, “Legend of the founding of Rome” and “Monarchy and republic” are all sub-sections of “History”).
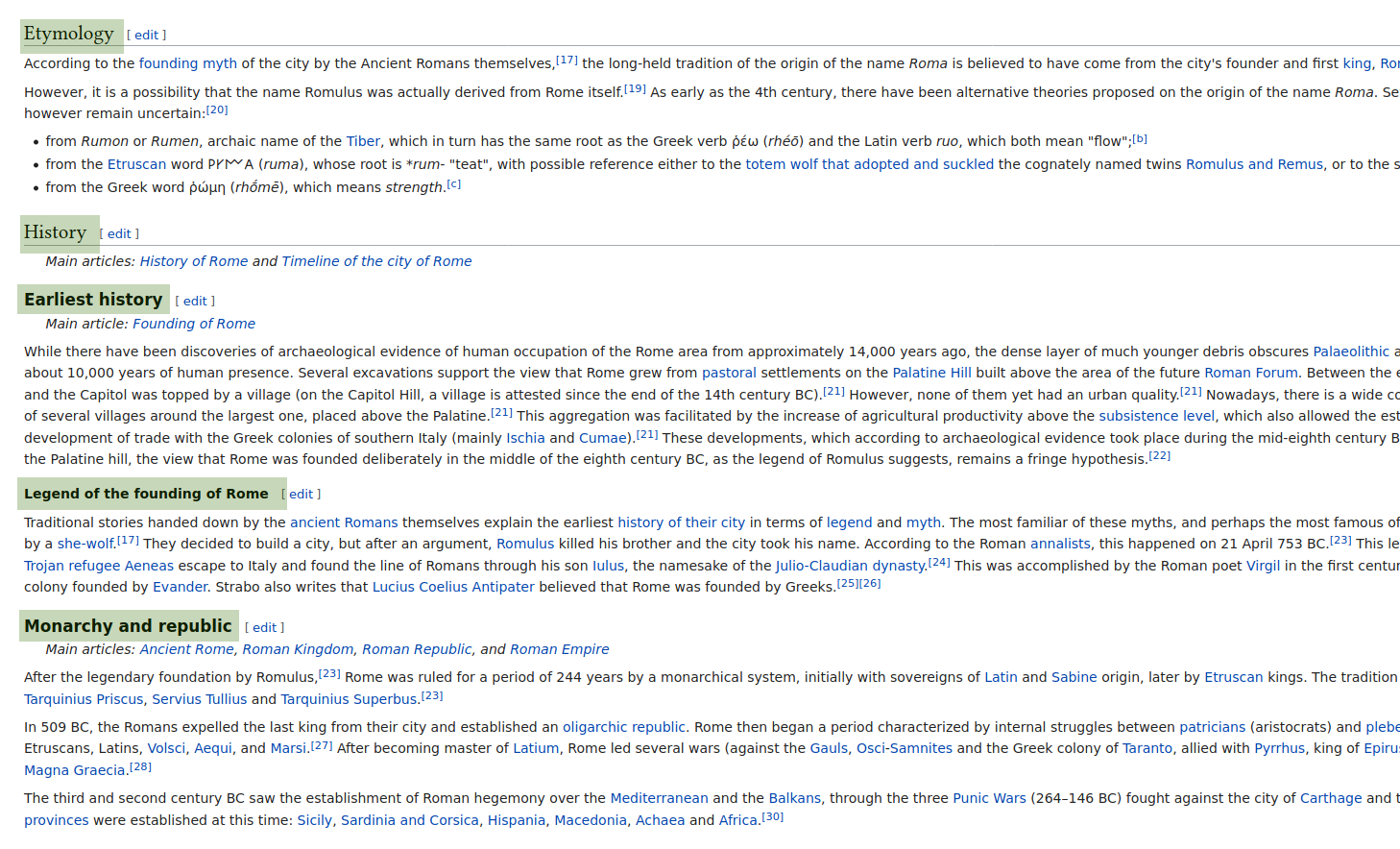
Our video will be divided into section that match those displayed in the page. In particular we will only take into account sub-sections. When the text for each sub-section is being spoken, we will want to display its name in the video.
For this reason, we want to separately extract each section and its text, rather than having just one huge blob of content. Besides this, we also want to extract images and link them to a specific sub-section, in order to show pictures that are more relevant to what is being talked about. Last but not least, some Wikipedia pictures have a caption that we will want to display as well, instead of just the bare picture.
All of this stuff can be done by parsing the HTML version of the page. At the end of this process we have a list of sections with text and pictures (possibly with captions).
Note: Wikipedia pages can be very long, resulting videos that are more than 1 hour long. To avoid this I also applied a very simple text summarization algorithm that removes some sentences until the result is of a desired length.
1.3 Retrieving additional content from Wikidata and Pixabay
Wikidata allows us to extract structured information for Wikipedia pages. If you are not familiar with Wikidata, just check its Rome entry to see what kind of information is available. It’s a lot of stuff!
We can use this to enrich our video with additional information. As an example, we are going to retrieve the flag of an entity and show it in the video as an overlay. Clearly, this will not show anything for entities that do not have a flag image property, but we can easily implement more properties using the same process.
Unfortunately, pictures from Wikipedia are often not enough for a video: many times they are not the best quality and several pages just have a few of them, so our video would basically consist in 3/4 pictures that last 2 minutes each. Pretty boring, huh? Fortunately, Pixabay has a fantastic API that allows us to retrieve free, open-domain pictures and videos based on a keyword search. With this, we can considerably increase the amount of pictures at our disposal and also include videos as well!
We will query Pixabay API and retrieve pictures for each section that we have extracted at the previous step. To try and get more relevant pictures, we will include the section title in the search query. For example, we will search for “Rome History” instead of just “Rome” when retrieving picture for the “History” section. If there are 0 results, we will use those for “Rome” instead. The same process is applied to videos.
1.4 Build a storyboard
We have a bunch of picture, videos and Wikipedia page sections. At this point, we can visualize what the video will look like by building a simple HTML page that will give us a preview.

1.5 Text-to-speech with Amazon Polly
This has really been one of the simplest step in the process. For each section, we send its text to Amazon Polly and save the output to an mp3 file that will be used as audio track. I tried several type of voices and I decided that the neural voice with a “conversational” was the one that sounded best.
To enable this setting, you need to send SSML instead of plaintext in your request. It will look like this:
<speak>
<amazon:domain name="conversational">Hello, this is a test!</amazon:domain>
</speak>
Just take care of escaping the text correctly if you don’t want to receive an InvalidSsml exception.
1.6 Rendering the video with ffmpeg
Now comes the trickiest part. Having no prior experience with ffmpeg I had to rely heavily on a series of very valuable StackOverflow questions.
What the system does is basically generate a very long ffmpeg command that will create the video based on input images, videos and audio tracks. This includes combining everything from the flag overlay that I mentioned earlier, the actual pictures/videos and the text overlays, like the name of the current section.
I’ve also managed to create simple effects like fade in/out between images and slight zoom motion for images.
2. Making the videos YouTube-ready
Now that we have are videos ready, we want somebody to see them. But, after all we went through to generate the video automatically, we really do not want to upload it manually to YouTube, having to fill all the metadata and choose a thumbnail image.
For this reason, the output of the program also includes a JSON file that contains information about the video. Most of this metadata is needed for YouTube APIs, such as a video title, description, tags, etc… The system will take care of automatically generating it, for example by choosing the first few sentences of the video as its description.
YouTube videos can also include coordinates of the geographical location they are filmed in, so we automatically extract and include those, if available, from Wikidata.
The only thing that’s left is to generate a thumbnail image. This and the upload to YouTube parts have actually been implemented by a friend of mine who joined me in this project.
His code will read the title (e.g. Rome) and subtitle (e.g. History, the topic of the video) fields in the JSON file and create a nice looking thumbnail image, by overlaying them to an picture taken from the video itself. This part it’s written in Golang and uses disintegration/imaging and fogleman/gg libraries. It will also take care of uploading the video to YouTube with all the metadata contained in the JSON file.
3. Conclusions
Of course, there are a lot of quirks that I didn’t mention in the article to keep it short and to the point (e.g., choosing the duration of the images according to the audio duration, avoid zooming on images that have a caption otherwise it goes out of the viewport, etc…). I didn’t want to go into probably boring implementation details, but if you have any question feel free to leave a comment below!

Great idea
When executing I am getting the error “java.lang.Runtime.exec(String)” because “exec” was deprecated, any advice on this? Thanks.
I’m not sure about it. Deprecated methods usually continue working and give a warning, but if that’s not the case you need to replace all those method calls with the correct one. Should be quite trivial for `exec` as it’s just running simple terminal commands and the replacement should be obvious. If you don’t wanna go this way maybe you can try compiling and running the code with an older version of Java where the method is not deprecated.